Com as plataformas de análise on-chain, os exploradores de blockchain e os Agentes de IA a impulsionar uma procura cada vez maior por dados on-chain, as redes de indexação de dados consolidaram-se como um pilar fundamental da infraestrutura Web3. Compreender as diferenças entre o SQD e o The Graph oferece uma visão mais clara sobre a orientação atual da camada de dados Web3 e as características distintivas das diferentes abordagens técnicas.
O que é o SQD
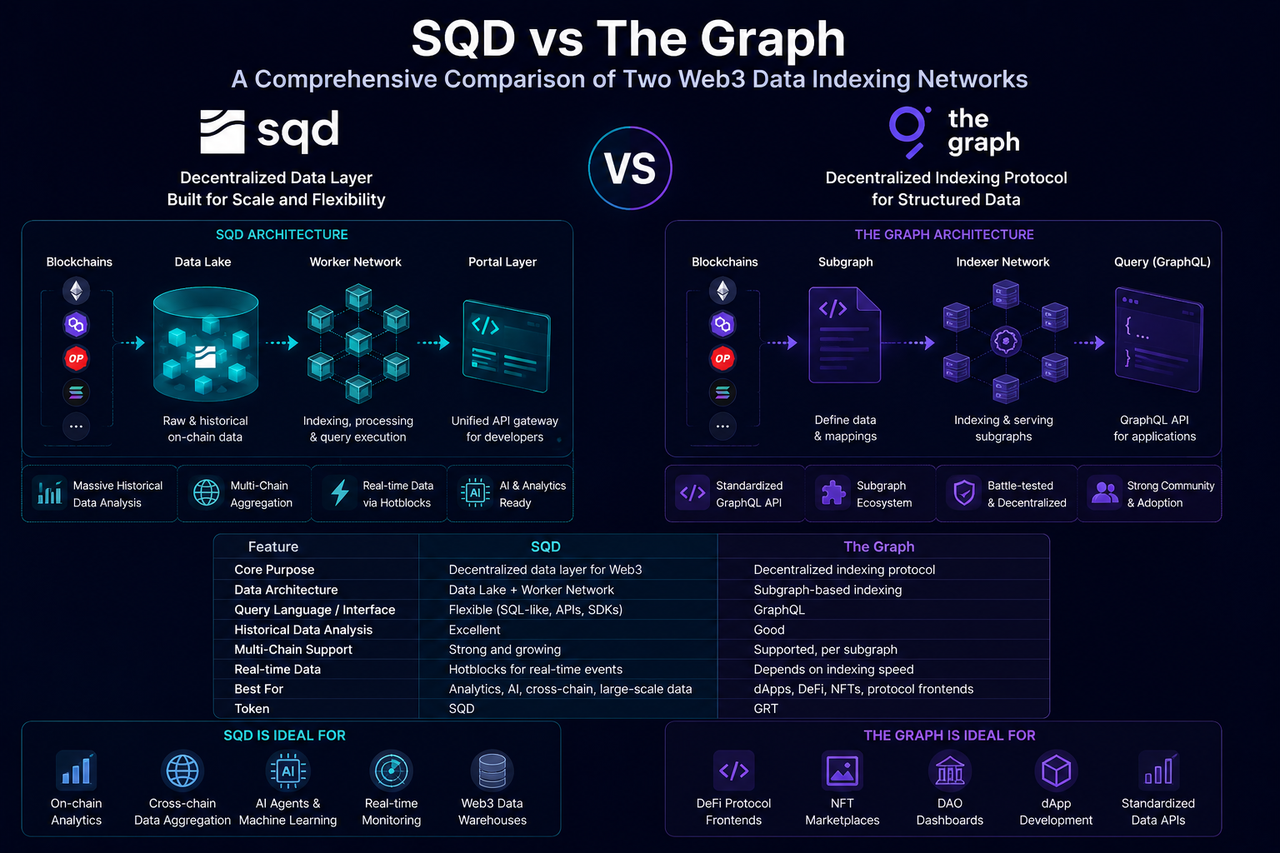
O SQD (Subsquid) é uma rede de dados blockchain descentralizada que estabelece uma estrutura de acesso aberto a dados através de um Data Lake, Worker Nodes e uma camada de consulta Portal. O seu principal objetivo é permitir que os programadores acedam rapidamente e analisem dados multi-cadeia sem necessidade de manter sistemas de indexação complexos.
Ao contrário das abordagens de indexação tradicionais, o SQD recolhe e armazena proativamente grandes volumes de dados históricos on-chain, a indexar e a executar consultas através dos Worker Nodes. Quando uma aplicação envia um pedido, a camada Portal agenda os recursos da rede e devolve resultados estruturados. Esta arquitetura posiciona o SQD mais como uma plataforma de dados descentralizada adaptada à Web3.
O que é o The Graph
O The Graph é um dos primeiros protocolos de indexação de dados a alcançar uma adoção em larga escala na Web3. O seu mecanismo principal utiliza Subgraphs para definir e indexar dados de protocolos ou aplicações específicas, que oferece aos programadores interfaces de consulta GraphQL.
Os programadores devem predefinir a estrutura de dados e os tipos de eventos a indexar. Os nodos indexadores sincronizam e processam dados on-chain de acordo com a configuração do Subgraph, o que gera, no final, conjuntos de dados consultáveis.
A filosofia do The Graph confere a cada aplicação a sua própria solução de indexação dedicada, a impulsionar uma utilização alargada nos ecossistemas DeFi, NFT e DAO.
Em que diferem as arquiteturas de dados?
A arquitetura de dados é uma das diferenças mais fundamentais.
O The Graph utiliza um modelo orientado por Subgraph. O programador define primeiro um modelo de dados, e depois a rede constrói os índices em conformidade — de forma semelhante a predefinir um esquema de base de dados antes de armazenar os dados.
O SQD adota uma arquitetura Data Lake. Grandes volumes de dados on-chain são ingeridos e armazenados uniformemente num Data Lake distribuído, com os Worker Nodes a processar os dados dinamicamente com base nas necessidades de consulta.
Em suma, o The Graph cria índices para aplicações específicas, enquanto o SQD cria um armazém de dados que abrange todo o ecossistema blockchain.
Em que diferem os métodos de consulta?
Os padrões de consulta afetam diretamente a experiência do programador e as capacidades da aplicação.
O The Graph baseia-se principalmente em interfaces GraphQL. Os programadores podem obter rapidamente resultados de dados predefinidos recorrendo a uma sintaxe padronizada. Este modelo funciona bem para aplicações com estruturas claras e lógica de consulta relativamente fixa.
O SQD dá ênfase a capacidades de consulta flexíveis. Os programadores podem aceder a dados pré-processados e realizar análises complexas de dados históricos e consultas agregadas multi-cadeia.
Para análise de dados em larga escala, o SQD oferece geralmente maior flexibilidade. Para construir interfaces de aplicação padronizadas, o The Graph tem a vantagem de um ecossistema maduro.
Em que difere o suporte multi-cadeia?
Com a Web3 a entrar na era multi-cadeia, o acesso a dados entre cadeias torna-se cada vez mais crítico.
O The Graph foi inicialmente desenvolvido em torno do ecossistema Ethereum e expandiu-se posteriormente para várias redes Layer 1 e Layer 2, exigindo geralmente configurações Subgraph correspondentes para cada cadeia.
O SQD foi concebido desde o início com a integração de dados multi-cadeia em mente. A sua estrutura unificada Data Lake permite que dados de diferentes blockchains sejam processados e consultados dentro de uma única estrutura.
Para aplicações que necessitam de análise entre cadeias, rastreio de ativos entre cadeias e acesso unificado a dados, a arquitetura do SQD simplifica significativamente a agregação multi-cadeia.
Em que difere o processamento de dados em tempo real?
Os sistemas de monitorização on-chain e os Agentes de IA exigem um elevado desempenho em tempo real.
O The Graph está assente principalmente na indexação e consulta de eventos; a sua capacidade em tempo real depende da velocidade de sincronização da indexação e das condições da rede.
O SQD adiciona uma camada de dados em tempo real, Hotblocks, ao seu Data Lake para processar novos blocos e eventos em direto. Isto permite-lhe abranger tanto a análise histórica como a monitorização em tempo real.
Para monitorização de transações, execução de estratégias automatizadas e transmissão de dados em tempo real, a arquitetura em tempo real do SQD oferece vantagens claras.
Em que difere a experiência do programador?
Ambas as soluções visam reduzir a barreira de acesso aos dados on-chain, mas seguem caminhos diferentes.
O ponto forte do The Graph é o seu sistema maduro de consulta GraphQL. Para equipas com experiência em desenvolvimento web, a curva de aprendizagem do GraphQL é relativamente baixa.
O SQD foca-se mais nas capacidades de análise de dados e na flexibilidade. Os programadores podem utilizar diretamente os recursos existentes do Data Lake sem construir um sistema de indexação completo para cada aplicação.
Se as necessidades forem maioritariamente interfaces de dados padronizadas, o The Graph é frequentemente mais fácil de começar. Se envolver análise complexa e processamento de dados multi-cadeia, o SQD oferece um acesso a dados mais rico.
Em que diferem as redes de nodos e os mecanismos de incentivo?
Ambas utilizam incentivos por token para sustentar as operações da rede.
A rede do The Graph é composta por Indexadores, Curadores e Delegadores. Os Indexadores tratam dos serviços de indexação e consulta; os outros participantes mantêm o ecossistema através de incentivos económicos.
A rede do SQD gira em torno de Worker Nodes, Prestadores de Serviços Portal e Delegadores. Os Worker Nodes são responsáveis pelo processamento de dados e execução de consultas, constituindo a camada de execução principal.
Embora ambas sejam redes de dados descentralizadas, a divisão de funções dos nodos e os mecanismos de coordenação de recursos diferem.
Para que cenários é o SQD mais adequado?
O SQD é mais adequado para:
- Plataformas de análise de dados multi-cadeia
- Sistemas de análise de comportamento on-chain
- Camadas de dados para Agente de IA
- Armazéns de dados blockchain
- Sistemas de monitorização em tempo real
- Análise de dados históricos em larga escala
Estes cenários exigem normalmente acesso a grandes quantidades de dados históricos e envolvem cálculos complexos e tarefas de agregação.
Para que cenários é o The Graph mais adequado?
O The Graph é mais adequado para:
- Frontends de protocolos DeFi
- Interfaces de dados de plataformas NFT
- Apresentações de dados DAO
- APIs Web3 padronizadas
- Serviços de dados de protocolos específicos
Estas aplicações têm normalmente estruturas de dados fixas e necessidades de consulta bem definidas.
SQD vs The Graph: Comparação principal
| Dimensão |
SQD |
The Graph |
| Posicionamento principal |
Camada de dados descentralizada |
Protocolo de indexação descentralizado |
| Arquitetura de dados |
Data Lake |
Subgraph |
| Modelo de consulta |
Consulta flexível |
Consulta GraphQL |
| Análise de dados históricos |
Forte |
Moderada |
| Agregação multi-cadeia |
Forte |
Moderada |
| Capacidade de dados em tempo real |
Suporte Hotblocks |
Depende da sincronização do índice |
| Funções dos nodos |
Rede de Worker Nodes |
Rede de Indexadores |
| Compatibilidade com Agente de IA |
Relativamente forte |
Média |
| Construção de interfaces de aplicação |
Forte |
Forte |
| Barreira de aprendizagem |
Moderada |
Relativamente baixa |
Resumo
O SQD e o The Graph são ambos representantes-chave da infraestrutura de dados Web3, mas seguem caminhos técnicos diferentes. O The Graph fornece serviços de indexação padronizados para aplicações específicas através de Subgraphs, com uma base madura nos ecossistemas DeFi e NFT. O SQD constrói uma plataforma de dados descentralizada de uso geral recorrendo a um Data Lake, a uma Rede de Worker Nodes e a uma camada de dados em tempo real, priorizando a análise de dados históricos, a agregação multi-cadeia e as capacidades de consulta complexa.
Numa perspetiva de desenvolvimento da indústria, estes dois modelos não são puramente concorrenciais. À medida que os dados Web3 continuam a crescer, tanto os serviços de consulta padronizados como as camadas de dados de uso geral se tornarão componentes importantes da infraestrutura blockchain.
Perguntas Frequentes
Qual é a maior diferença entre o SQD e o The Graph?
A maior diferença reside na arquitetura de dados. O The Graph constrói índices ao nível da aplicação com base em Subgraphs, enquanto o SQD constrói uma camada de dados de uso geral recorrendo a um Data Lake distribuído e a uma Rede de Worker Nodes. Isto leva a diferenças claras na organização dos dados e nos métodos de consulta.
O SQD pode substituir o The Graph?
Os problemas que resolvem sobrepõem-se parcialmente, mas os seus objetivos de design diferem. O The Graph é melhor para construir interfaces de dados padronizadas, enquanto o SQD se destaca na análise complexa e no acesso a dados multi-cadeia. Portanto, não existe uma relação de substituição direta.
Porque é que os Agentes de IA têm mais interesse no SQD?
Os Agentes de IA precisam normalmente de aceder a grandes quantidades de dados históricos e informações multi-cadeia. A arquitetura Data Lake do SQD e as suas capacidades de consulta flexíveis podem fornecer fontes de dados mais ricas para sistemas de IA.
O The Graph suporta dados multi-cadeia?
Sim. O The Graph expandiu-se para várias redes blockchain, mas normalmente exige configurações Subgraph correspondentes para diferentes redes.
Porque é que o SQD utiliza uma arquitetura Data Lake?
Um Data Lake pode armazenar uniformemente dados históricos on-chain em larga escala e suportar análises flexíveis posteriormente. Esta arquitetura é mais adequada para cenários de consulta complexa e agregação de dados entre cadeias.
Devem os programadores escolher o SQD ou o The Graph?
A escolha depende das necessidades específicas. Se a prioridade forem interfaces de dados de protocolo padronizadas, o The Graph é uma solução madura. Se for necessária análise complexa, integração de dados multi-cadeia ou suporte para camadas de dados de IA, o SQD tem vantagem.







