À medida que as aplicações de blockchain escalam, os dados on-chain tornaram-se um recurso fundamental para DeFi, análise on-chain, Agentes de IA e aplicações multi-chain. No entanto, os dados brutos da blockchain existem tipicamente sob a forma de blocos, transações e registos de eventos, obrigando os programadores a passar por pipelines complexos de extração e processamento antes de os poderem utilizar. Aceder eficientemente a dados on-chain tornou-se, por isso, um desafio central no desenvolvimento da infraestrutura Web3.
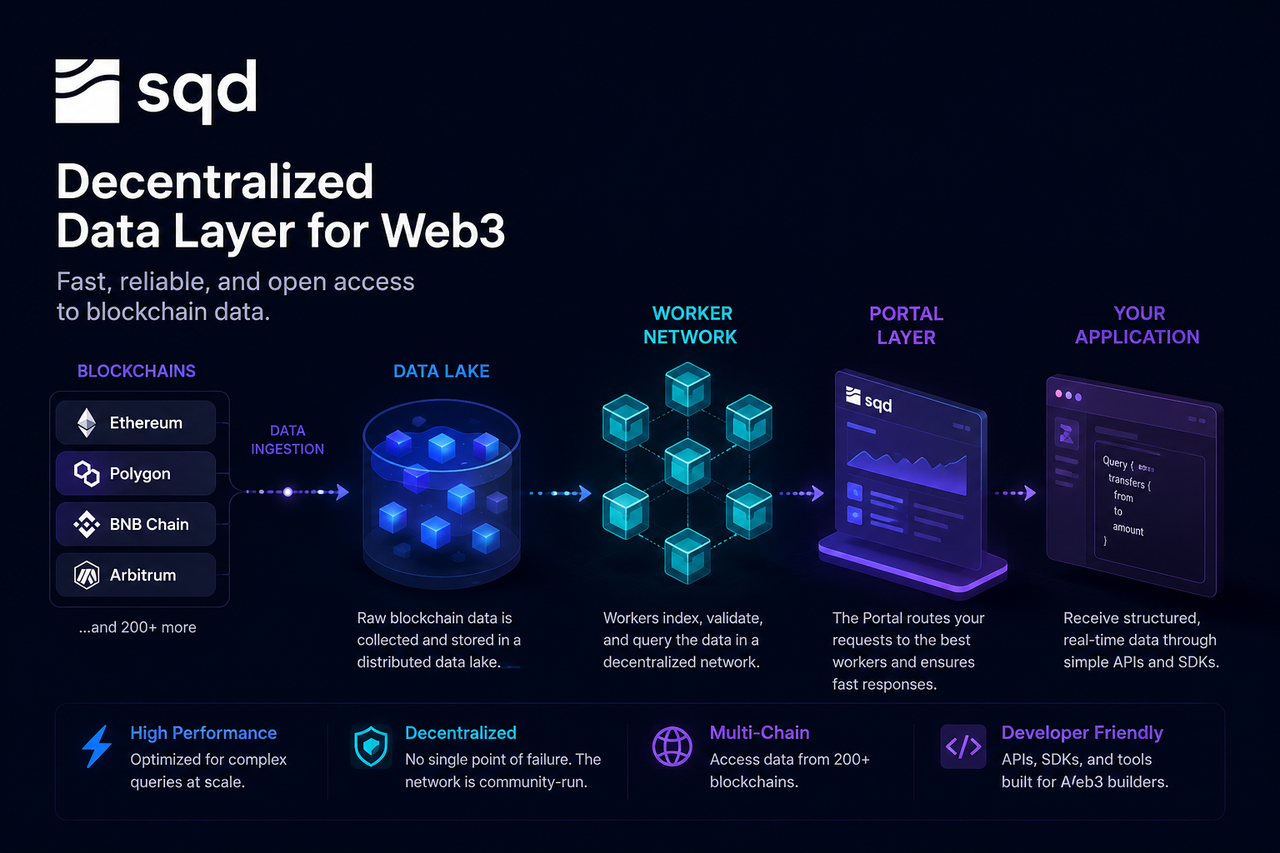
O Subsquid (SQD) surge como uma rede de dados descentralizada concebida para resolver este problema. Ao contrário dos nodos RPC tradicionais, que leem o estado da blockchain diretamente, o SQD oferece uma arquitetura de serviço de dados construída em torno de um lago de dados, de nodos de trabalho e de uma camada de consulta Portal, permitindo aos programadores aceder a dados on-chain estruturados e indexados através de uma interface unificada.
O que é uma consulta de dados SQD?
Uma consulta de dados SQD é o processo através do qual os programadores recuperam dados on-chain através da Rede SQD. Em vez de solicitar dados diretamente aos nodos da blockchain, as consultas SQD devolvem dados que já foram pré-processados e indexados, permitindo respostas rápidas a pedidos complexos.
Por exemplo, um painel DeFi pode precisar de agregar volumes de negociação dos últimos meses, um Agente de IA pode precisar de ler alterações de ativos em vários endereços e uma plataforma de análise pode precisar de consultar todo o histórico de eventos de um contrato inteligente específico. Todos estes são cenários típicos de consulta de dados.
A ideia central do SQD é deslocar o processamento pesado de dados para um passo inicial, para que as aplicações possam aceder diretamente a dados estruturados sem terem de lidar com grandes volumes de dados brutos de blocos.
Como os dados on-chain entram na Rede SQD
O ponto de partida de uma consulta ocorre, na verdade, antes de o programador enviar o pedido.
À medida que as redes blockchain geram constantemente novos blocos, a Rede SQD captura dados brutos — incluindo blocos, transações, registos de eventos e alterações de estado de contratos inteligentes — em tempo real através do seu sistema de recolha de dados. Estes dados são depois padronizados para posterior processamento e armazenamento.
Como o SQD suporta várias blockchains, a sua camada de recolha de dados deve sincronizar continuamente fluxos de dados de diferentes ecossistemas, garantindo simultaneamente a integridade e consistência dos dados. Após a padronização, os dados são escritos na camada de armazenamento da rede.
O lago de dados é a infraestrutura de armazenamento central na rede SQD.
Ao contrário das bases de dados tradicionais, concebidas para dados estruturados, um lago de dados pode lidar com grandes quantidades de dados brutos e semiestruturados. O histórico da blockchain, dados de transações, registos de eventos e instantâneos de estado são todos armazenados nesta camada.
A vantagem de um lago de dados é que preserva o histórico completo dos dados, permitindo simultaneamente um processamento e análise flexíveis a jusante. Para aplicações que precisam de rastrear milhões de transações, este método de armazenamento é muito mais eficiente do que consultar diretamente os nodos da blockchain.
O lago de dados funciona como a memória de longo prazo da Rede SQD, fornecendo dados para indexação e consultas subsequentes.
Os nodos de trabalho são a camada de execução na rede SQD.
Quando os dados entram na rede, os nodos de trabalho indexam-nos, classificam-nos e otimizam-nos para uma recuperação rápida. O processo de indexação é como criar um índice para uma enorme enciclopédia — não é necessário percorrer tudo de novo em cada consulta.
Para além de construir índices, os nodos de trabalho também executam tarefas de consulta. Quando um programador solicita dados específicos, um nodo de trabalho localiza rapidamente os registos relevantes usando o índice e depois filtra, agrega e calcula os resultados.
Como vários nodos de trabalho podem funcionar em paralelo, a rede pode lidar com muitas consultas simultaneamente, aumentando o desempenho e a escalabilidade globais.
Como o Portal recebe os pedidos dos programadores
O Portal é o ponto de entrada unificado para os programadores acederem à Rede SQD.
Os programadores enviam normalmente consultas através de uma API ou SDK, sem se ligarem diretamente aos nodos subjacentes. Quando um pedido chega ao Portal, o sistema analisa a consulta e determina quais os nodos de trabalho mais adequados para a processar.
O Portal funciona como um balanceador de carga na internet. Os programadores interagem apenas com uma única interface, enquanto a complexa gestão de recursos e seleção de nodos ocorre automaticamente nos bastidores.
Este design simplifica o desenvolvimento e melhora a eficiência global de recursos da rede.
Como os resultados das consultas são devolvidos às aplicações
Assim que os nodos de trabalho terminam o processamento, os resultados são enviados de volta para a camada Portal.
O Portal formata os resultados conforme necessário e envia os dados finais para a aplicação. Os programadores recebem dados já estruturados — por exemplo, objetos JSON ou resultados analíticos — prontos para exibição no front-end, lógica de negócio ou inferência de IA.
Todo o processo é geralmente transparente para os utilizadores finais. Estes veem simplesmente a página carregar ou os resultados da análise aparecerem, enquanto nos bastidores já ocorreram vários passos, desde a recolha de dados até à execução da consulta.
Como o Hotblocks suporta consultas de dados em tempo real
Para além das consultas históricas, muitas aplicações necessitam de informações on-chain em tempo real.
Por exemplo, sistemas de monitorização on-chain precisam de detetar transações anómalas, estratégias automatizadas precisam de ouvir eventos de contratos inteligentes e os Agentes de IA precisam de estar a par das condições de mercado mais recentes. Estes cenários exigem que os dados estejam disponíveis assim que um novo bloco é produzido.
O Hotblocks é a camada de dados em tempo real que o SQD fornece, especificamente concebida para novos blocos e eventos ao vivo. Em comparação com os dados históricos no lago de dados, o Hotblocks foca-se na baixa latência e respostas rápidas, permitindo aos programadores construir aplicações em tempo real.
Como as consultas SQD diferem das consultas RPC tradicionais
Ambos os métodos permitem aceder a dados on-chain, mas a lógica subjacente é muito diferente.
Os nodos RPC tradicionais são como consultar diretamente uma base de dados blockchain. Cada pedido tem de procurar os dados correspondentes a partir do estado on-chain ou de registos históricos. À medida que o âmbito da consulta cresce, a pressão sobre o desempenho e os custos aumenta proporcionalmente.
O SQD, por outro lado, utiliza uma arquitetura pré-indexada. Os dados já estão organizados e indexados quando entram na rede, pelo que as consultas não precisam de percorrer todo o histórico novamente. Para análises complexas, agregação de dados multi-chain e estatísticas históricas de longo prazo, o SQD oferece tipicamente uma eficiência muito superior.
| Dimensão |
SQD |
RPC Tradicional |
| Fonte de dados |
Dados pré-indexados |
Leituras on-chain em tempo real |
| Eficiência de consulta |
Elevada |
Média |
| Análise de dados históricos |
Vantagem significativa |
Mais complexa |
| Suporte multi-chain |
Forte |
Depende de vários nodos |
| Custo de infraestrutura |
Menor |
Maior |
| Leitura de estado em tempo real |
Suportada |
Suportada |
Como o processo de consulta SQD é relevante para os Agentes de IA
Os Agentes de IA estão a tornar-se uma aplicação central na infraestrutura Web3, e o acesso a dados é fundamental para o seu funcionamento.
Se um Agente de IA precisar de analisar o comportamento de carteiras, acompanhar estados de protocolos ou executar ações on-chain, tem de obter continuamente dados precisos e estruturados. As consultas RPC tradicionais podem fornecer dados brutos, mas geralmente exigem processamento e transformação adicionais.
A interface de dados unificada fornecida pelo SQD reduz a complexidade para os Agentes de IA obterem informações on-chain. Com resultados de consulta padronizados, os sistemas de IA podem dedicar mais poder computacional à análise e tomada de decisões, em vez de se ocuparem com a manipulação de dados.
À medida que a IA e a Web3 continuam a convergir, a importância das camadas de dados descentralizadas só aumentará.
Resumo
Uma consulta de dados SQD não é apenas uma simples leitura de dados — é um fluxo de trabalho completo que envolve a camada de recolha de dados, o lago de dados, os nodos de trabalho e a camada Portal, todos a funcionar em conjunto. Os dados brutos da blockchain são primeiro recolhidos e armazenados, depois indexados e otimizados, e finalmente entregues aos programadores através de uma interface unificada.
Este modelo de processamento distribuído e pré-indexado permite ao SQD oferecer elevada eficiência para consultas complexas, análise multi-chain e acesso a dados em tempo real. À medida que as plataformas DeFi, de análise on-chain e os Agentes de IA exigem cada vez mais dados, a arquitetura de camada de dados representada pelo SQD está a tornar-se uma parte essencial da infraestrutura Web3.
Perguntas Frequentes
Qual é a diferença entre uma consulta de dados SQD e uma consulta API normal?
Uma API normal é geralmente mantida por um fornecedor centralizado, enquanto uma consulta SQD é executada numa rede de dados descentralizada. Os dados SQD provêm de sistemas de recolha e indexação on-chain, oferecendo um acesso a dados mais aberto e verificável.
Porque é que a velocidade das consultas SQD é mais rápida do que a de alguns pedidos RPC?
O SQD conclui a indexação e organização antecipadamente, pelo que as consultas não precisam de reexaminar grandes quantidades de histórico de blocos. Para tarefas de análise complexa e dados históricos, o SQD é geralmente muito mais rápido.
Qual é o papel dos nodos de trabalho no processo de consulta?
Os nodos de trabalho tratam da indexação, filtragem, agregação e cálculo. Quando o Portal recebe um pedido de consulta, os nodos de trabalho relevantes executam o processamento real dos dados.
Qual é a diferença entre um lago de dados e uma base de dados?
Uma base de dados armazena tipicamente dados estruturados, enquanto um lago de dados pode armazenar grandes volumes de dados brutos e semiestruturados. O SQD utiliza um lago de dados para armazenar o histórico completo on-chain, suportando consultas e análises flexíveis.
O Hotblocks pode substituir as consultas de dados históricos?
Não. O Hotblocks foi concebido para acesso a dados em tempo real; as consultas históricas continuam a depender do lago de dados e do sistema de indexação. Juntos, formam a capacidade completa de serviço de dados do SQD.
Que aplicações são mais adequadas para os serviços de consulta SQD?
Painéis DeFi, exploradores de blockchain, plataformas de análise on-chain, sistemas de monitorização em tempo real, aplicações multi-chain e Agentes de IA — qualquer cenário que necessite de acesso frequente a dados on-chain — são ideais para os serviços de consulta SQD.







